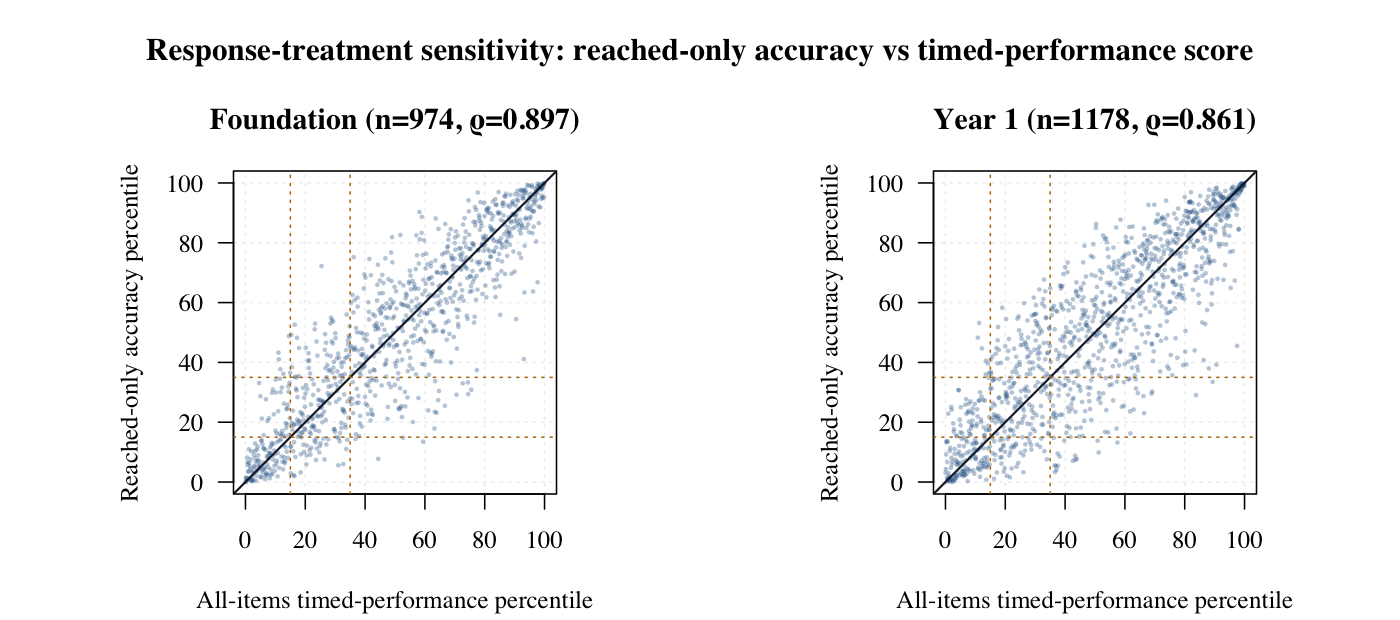
Reached response accuracy
Score what students answered correctly among valid reached responses. Cleaner as an accuracy or ability claim, but can understate timed productivity concerns.
A concise comparison of candidate methods for reporting 2026 Beginning-of-Year early numeracy screener performance, with provisional judgements organised around subtest representation, precision and uncertainty, and classification stability.
This memo compares scoring methods for two decisions: the single global BOY score and the student-level subtest scores. The immediate reporting need is one global score for dashboard labels and bands, plus a defensible way to describe subtest profiles.
The longer-term direction is a two-axis accuracy × pace report, but that architecture is not the immediate BOY single-score decision.
| Method | Description | Subtest representation | Precision / uncertainty | Classification stability |
|---|---|---|---|---|
| All-items timed-performance IRT | Unidimensional + testlet model. One global score from all retained items. Timed subtests use timed-performance scoring. | ◐Uses all included items, but longer subtests naturally carry more influence. | ●Student-level uncertainty is available; strongest fit for a global score precision story. | ●Current benchmark for movement checks. Stability must be read against challengers, not assumed as validity. |
| Equal-subtest timed-performance IRT | One global IRT score, with item contributions weighted so each subtest has equal design influence. | ●Balances all five subtests by design. | ●Student-level uncertainty is available; check whether equal weighting changes precision near cut points. | ◐Compare against all-items timed-performance IRT using percentile movement and high-concern cut-point crossings. |
| Hierarchical global-plus-subtest timed-performance model | Joint model estimating a general score plus subtest-specific deviations. | ●Represents all subtests and explicitly models subtest profiles. | ●Strong posterior uncertainty story, especially for subtest profiles and shrinkage. | △Compared with all-items timed-performance IRT, the global score can move students materially. Global use needs explicit justification. |
| Equal-subtest raw-score composite | Each subtest is scored directly from responses, then standardised and averaged equally. | ●Transparent equal-subtest representation. | △Limited uncertainty handling; short subtests can have coarse score resolution and many ties. | ◐Useful as a sanity check, not a strong standalone psychometric endpoint. |
| Selected-subtest reliability-weighted marker | Separate subtest calibrations. A selected subset feeds the global ability marker, weighted by reliability. Pace/fluency is separate. | ◐Only selected subtests contribute to global ability. That selection is a major construct decision. | ◐Reliability weights favour more precise selected subtests; uncertainty from excluded subtests is not represented. | ○The deck reviewed appears to use a 2025 cohort base. Run a 2026 comparison before treating it as a BOY scoring option. |
Reached-only accuracy versus timed-performance scoring. This shows how much the global score depends on treating trailing unreached timed items as zero credit.
Selected-subtest reliability-weighted marker versus all-items timed-performance IRT global score. The two panels show Foundation and Year 1 students matched by student ID. The logit view adds marginal histograms above and to the right of each scatter to show each method's score distribution.


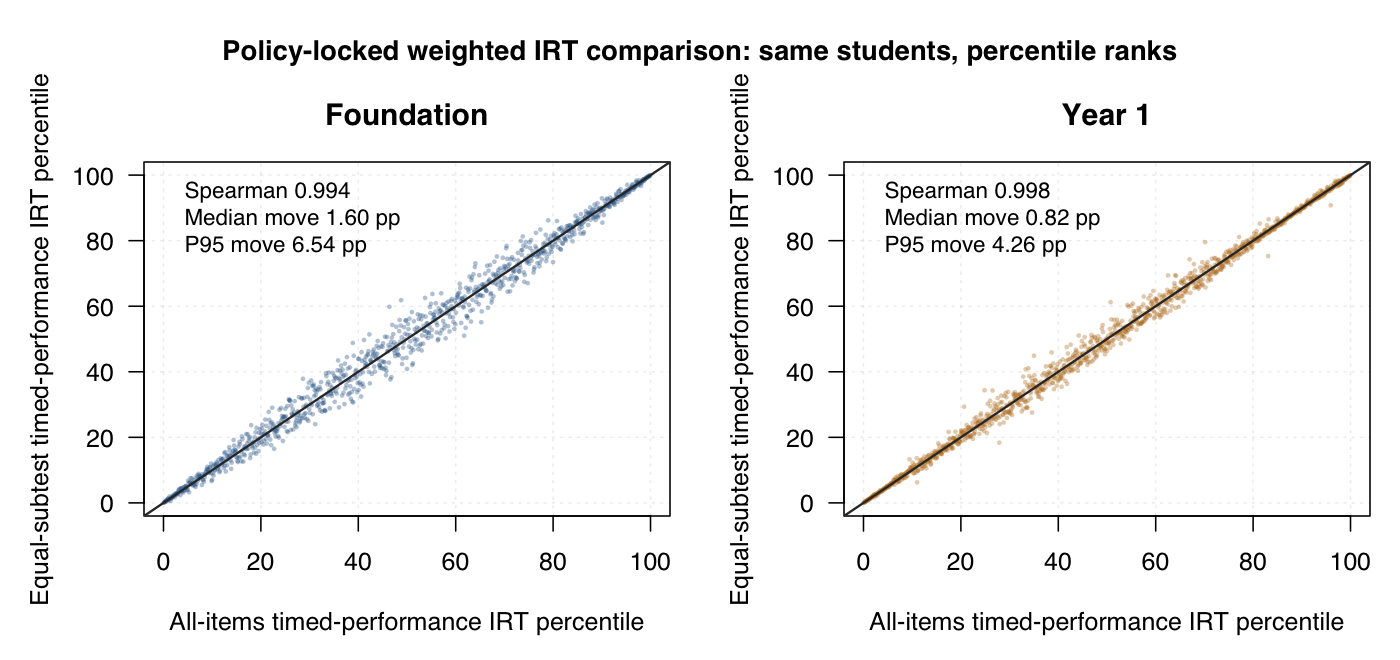
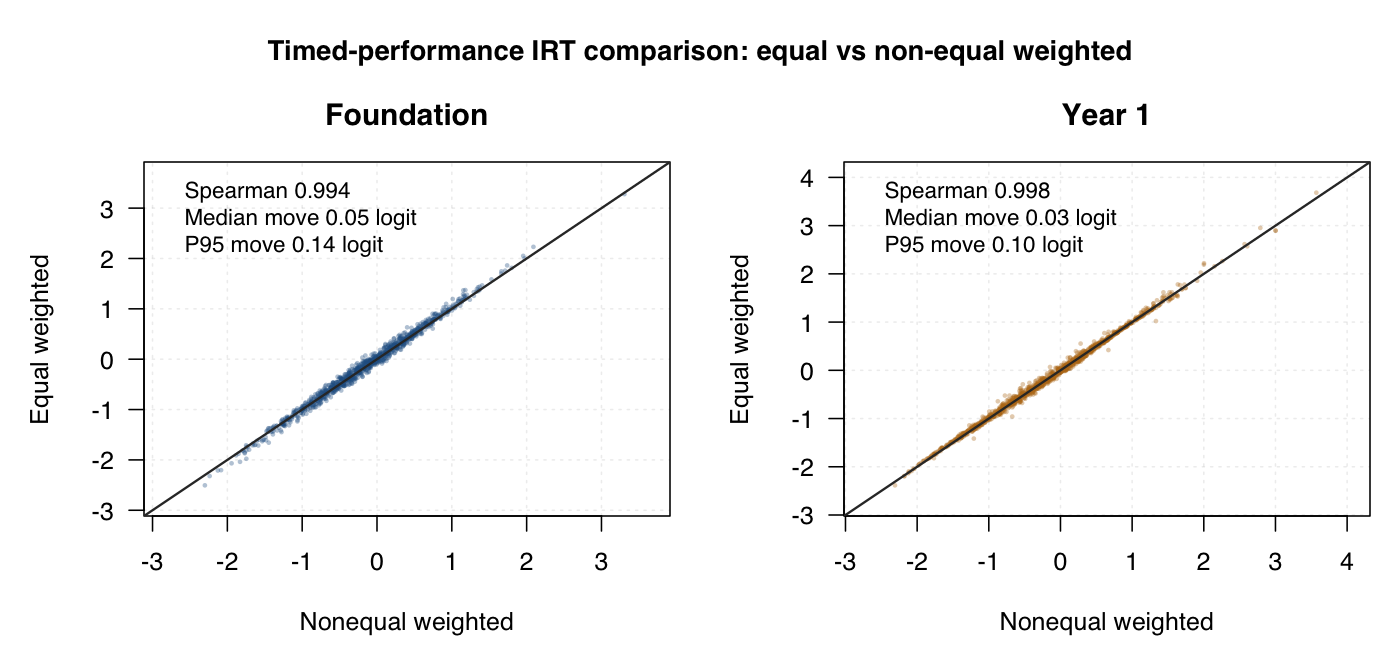
Equal-weighted timed-performance IRT versus nonequal weighted timed-performance IRT. These scatters use the completed policy-locked Stan score files, with the same students matched by student ID. Default view uses within-year percentile ranks.
Reliability is useful for deciding which subtests are precise enough to contribute to a selected-subtest marker, but the 2025 and 2026 statistics below are not identical measurement objects. The 2025 table summarises the external reference deck’s model diagnostics; the 2026 table uses current BOY empirical reliability proxies from the audit run.
| Year level | Subtest | 2025 marker status | Reliability / precision statistic | Read |
|---|---|---|---|---|
| Foundation | BNL0-20 | ●Selected | Continuous Rasch card: person θ SD 0.789; no EAP reliability shown in the extracted card. | Selected as part of the 2025 global ability marker. |
| Foundation | MC0-20 | ●Selected | EAP reliability 0.656; PSI 0.547; α 0.968. | Strong retained magnitude-comparison component. |
| Foundation | DMT10V2 | ●Selected | EAP reliability 0.489; PSI 0.537; α 0.486. | Selected in the 2025 marker, but individual reliability was modest. |
| Foundation | MQ1-20 | △Provisional / excluded | EAP reliability 0.615; WLE PSI 0.241; α 0.453. | Excluded from the 2025 marker pending item-level revision. |
| Foundation | MNA0-20 | △Provisional / excluded | EAP reliability 0.485; WLE PSI 0.000; α 0.708. | Excluded from the 2025 marker because person separation was weak. |
| Year 1 | BNL0-100 | ●Selected | Continuous Rasch card: person θ SD 0.641; no EAP reliability shown in the extracted card. | Selected as part of the 2025 global ability marker. |
| Year 1 | MC0-100 | ●Selected | EAP reliability 0.659; PSI 0.550; α 0.968. | Strong retained magnitude-comparison component. |
| Year 1 | ASMC | ●Selected | EAP reliability 0.668; PSI 0.530; α 0.661. | Selected arithmetic component in the 2025 marker. |
| Year 1 | AAMC | △Provisional / excluded | EAP reliability 0.554; WLE PSI 0.000; α 0.824. | Excluded from the 2025 marker pending revision. |
| Year 1 | MNA0-100 | △Provisional / excluded | EAP reliability 0.444; WLE PSI 0.000; α 0.793. | Excluded from the 2025 marker because person separation was weak. |
2025 global ability marker summary from the reference deck: Foundation selected BNL0-20 + MC0-20 + DMT10V2, composite reliability 0.759, α lower bound 0.532, mean inter-subtest r 0.275. Year 1 selected BNL0-100 + MC0-100 + ASMC, composite reliability 0.838, α lower bound 0.645, mean inter-subtest r 0.380.
| Year level | Subtest | 2026 reliability proxy | Floor / ceiling proxy | Selected-marker implication |
|---|---|---|---|---|
| Foundation | MQ1-20 | 0.582 | 2.8% / 0.0% | △Exclude under ≥ .70 rule. |
| Foundation | MC0-20 | 0.896 | 0.4% / 0.0% | ●Include; strong reliability signal. |
| Foundation | MNC0-20 | 0.830 | 4.8% / 0.0% | ●Include; strong reliability signal. |
| Foundation | DMT10_2026 | 0.584 | 0.0% / 9.2% | △Exclude under ≥ .70 rule. |
| Foundation | BNL0-20 | 0.704 | 0.6% / 0.0% | ◐Marginal include under ≥ .70; exclude under stricter ≥ .80. |
| Year 1 | MC0-100 | 0.902 | 0.6% / 0.0% | ●Include; strong reliability signal. |
| Year 1 | MNC0-100 | 0.839 | 1.4% / 0.0% | ●Include; strong reliability signal. |
| Year 1 | AAMC | 0.870 | 2.7% / 0.0% | ●Include under 2026 screen. |
| Year 1 | ASMC | 0.816 | 10.9% / 0.0% | ◐Include, with floor-rate caution. |
| Year 1 | BNL0-100 | 0.743 | 0.4% / 0.0% | ◐Marginal include under ≥ .70; exclude under stricter ≥ .80. |
Directional read: Foundation 2026 points to a narrower reliability-screened marker than the 2025 reference set; Year 1 2026 supports broader coverage, with BNL0-100 the marginal inclusion.
| Method | Description | Subtest representation | Precision / uncertainty | Classification stability |
|---|---|---|---|---|
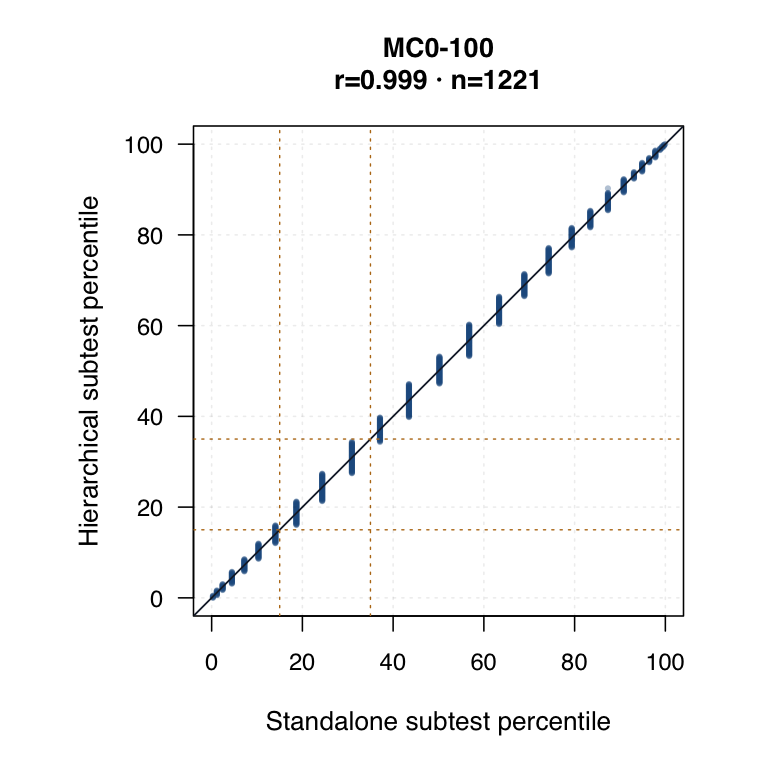
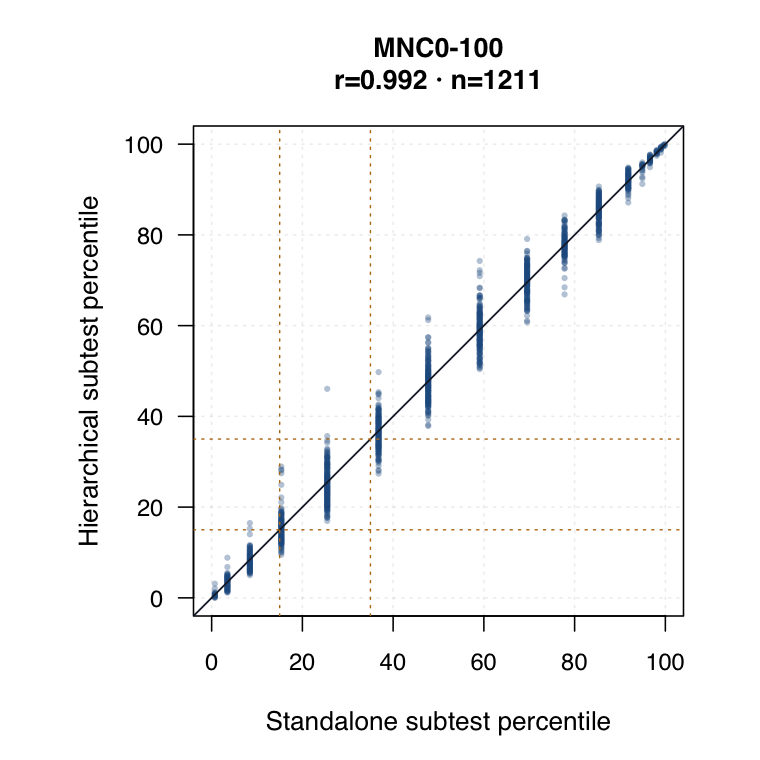
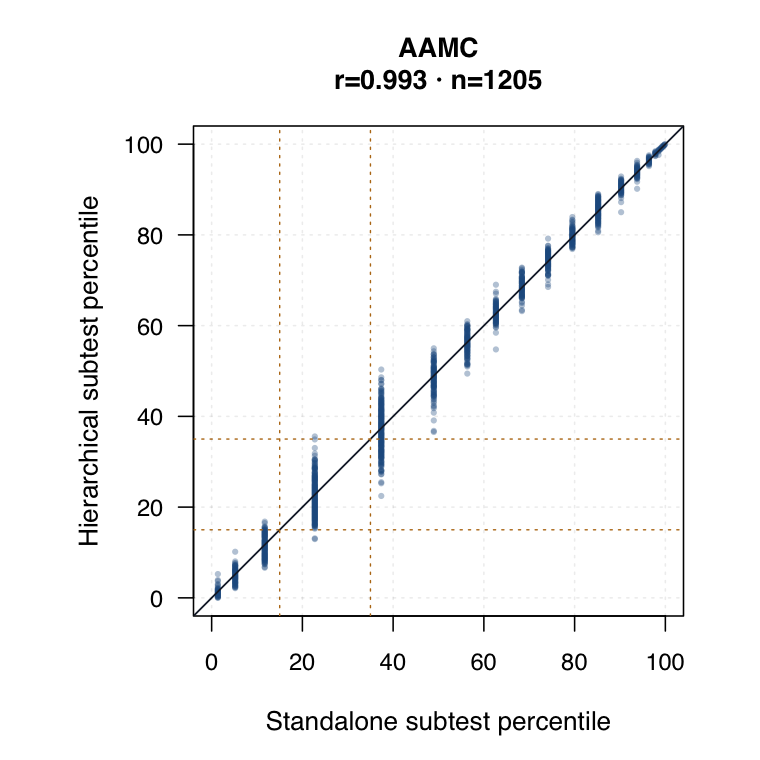
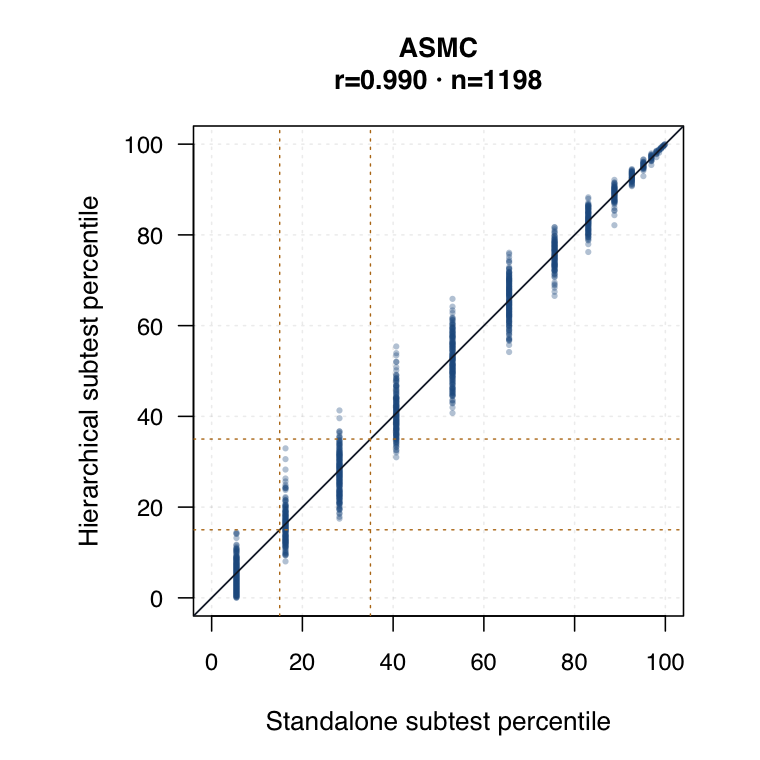
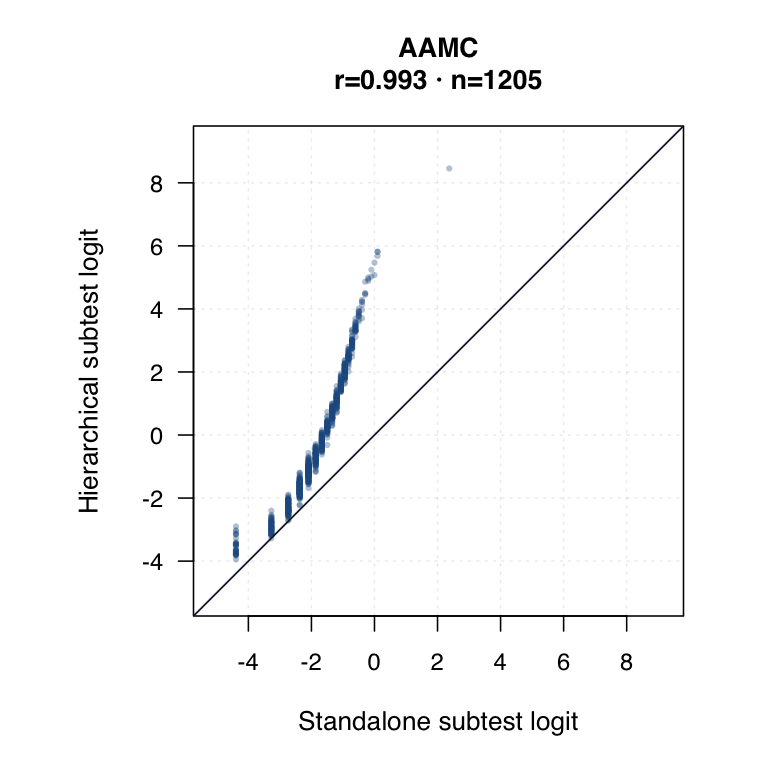
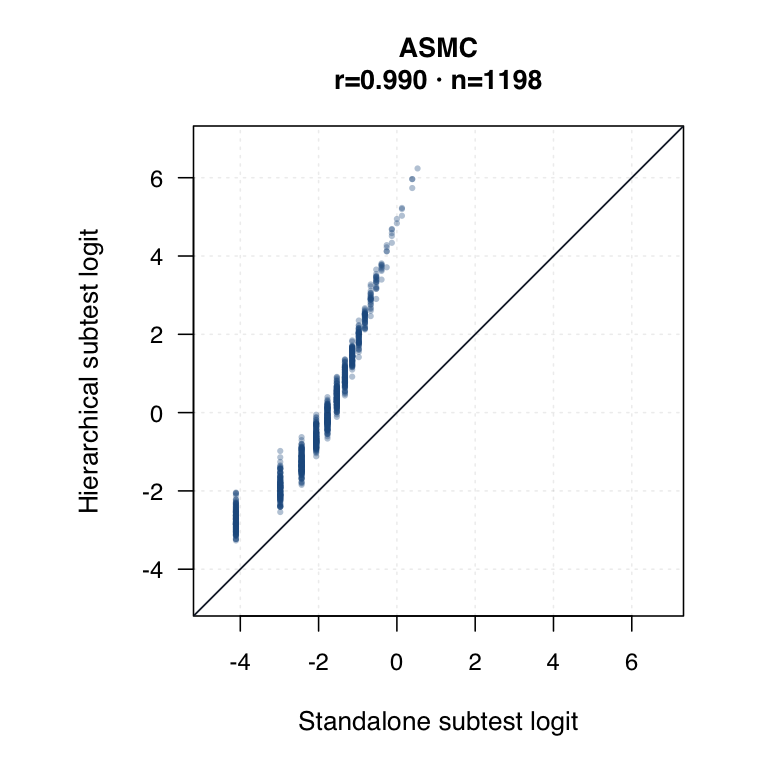
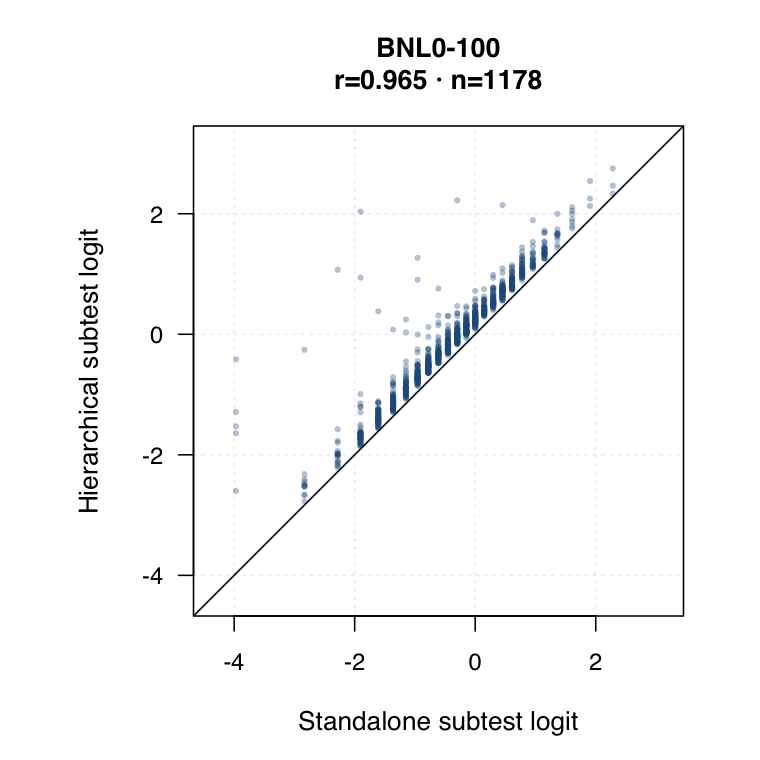
| Standalone subtest IRT | Each subtest is modelled separately. Timed subtests use timed-performance inputs where applicable. | ●Clean subtest-specific score for each probe. | ◐Subtest SEs are available, but the method does not borrow information across subtests. | ○Compare directly against hierarchical subtest scores by same student ID. |
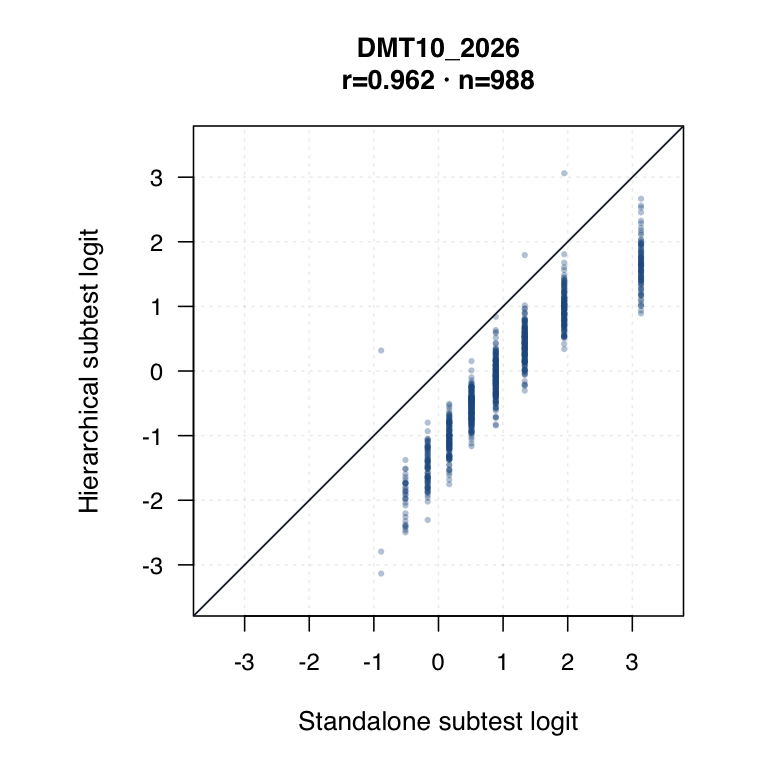
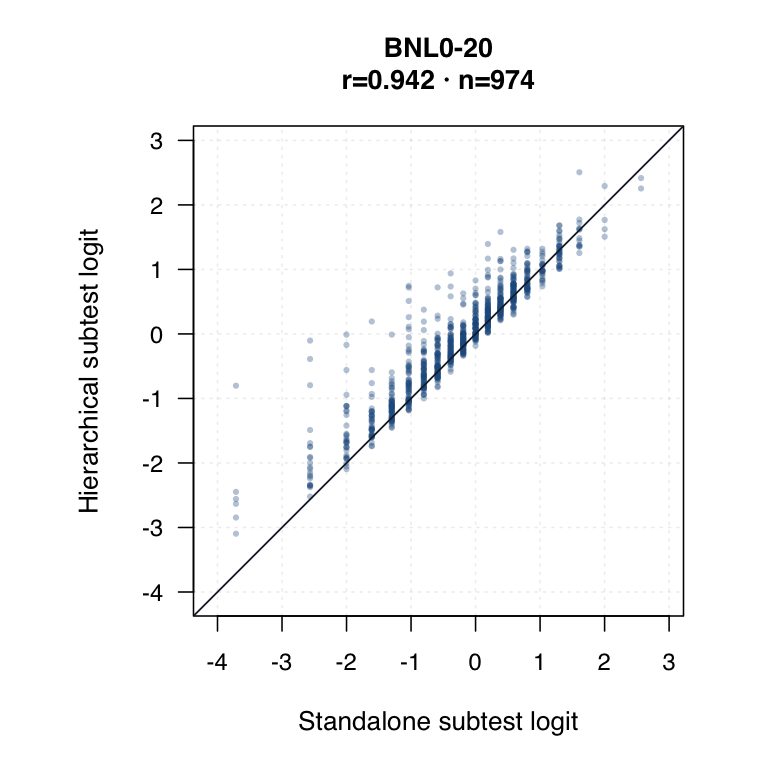
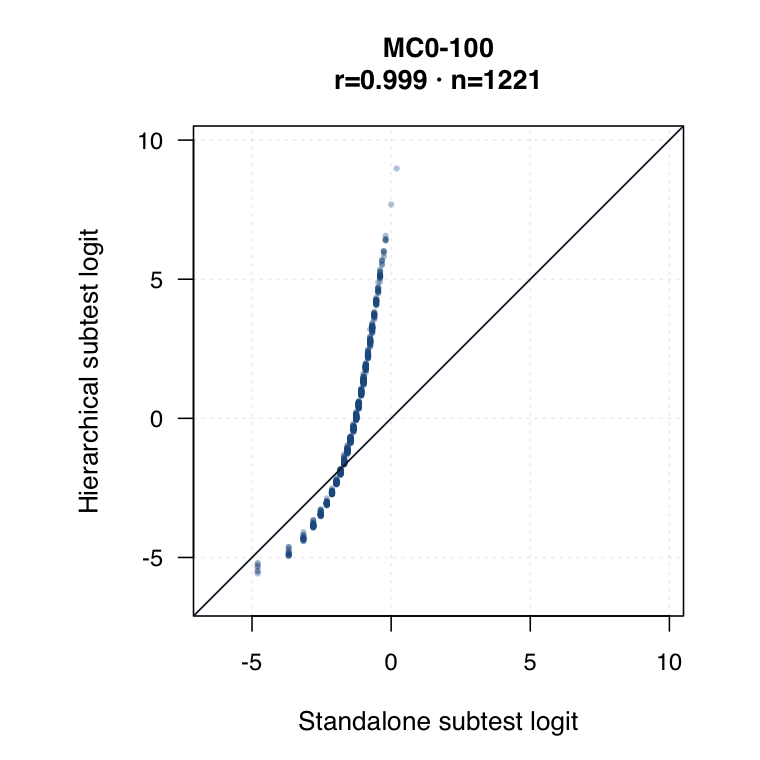
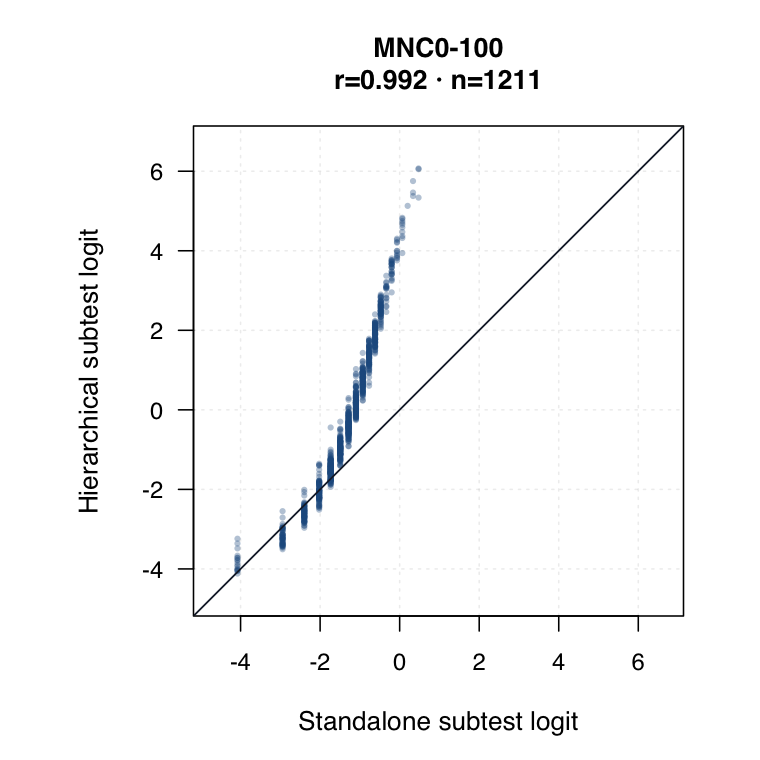
| Hierarchical modelled subtest scores | Subtest scores are estimated inside the joint model as general level plus subtest-specific deviation. | ●Represents all subtests while modelling each student’s profile. | ●Posterior uncertainty and shrinkage make this strongest for uncertainty-qualified subtest profiles. | ◐May shift subtest interpretation relative to standalone IRT. Needs same-student agreement review. |
| Raw/proportion subtest scores | Direct score from responses, such as correct over denominator or reached accuracy. | ●Highly transparent for teachers and audit. | △Transparent, but uncertainty is mostly denominator size, discreteness and tied-score behaviour. | ◐Useful companion method, but should not be the only evidence for subtest bands. |
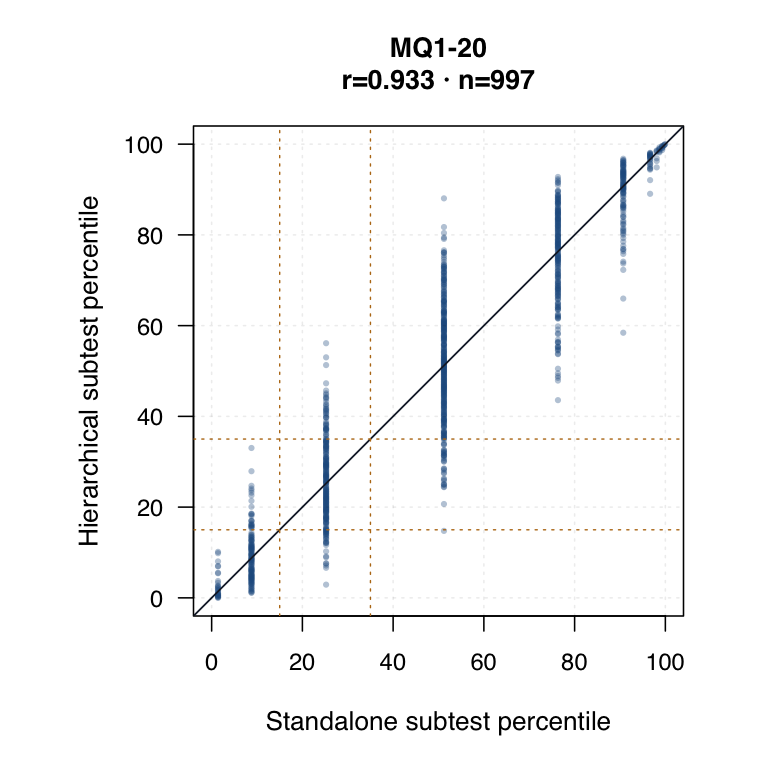
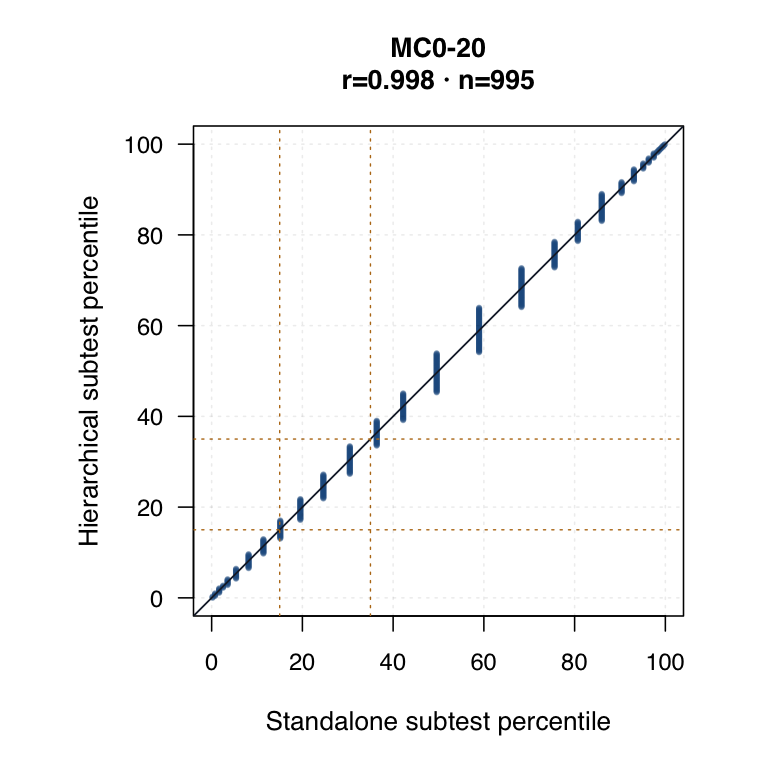
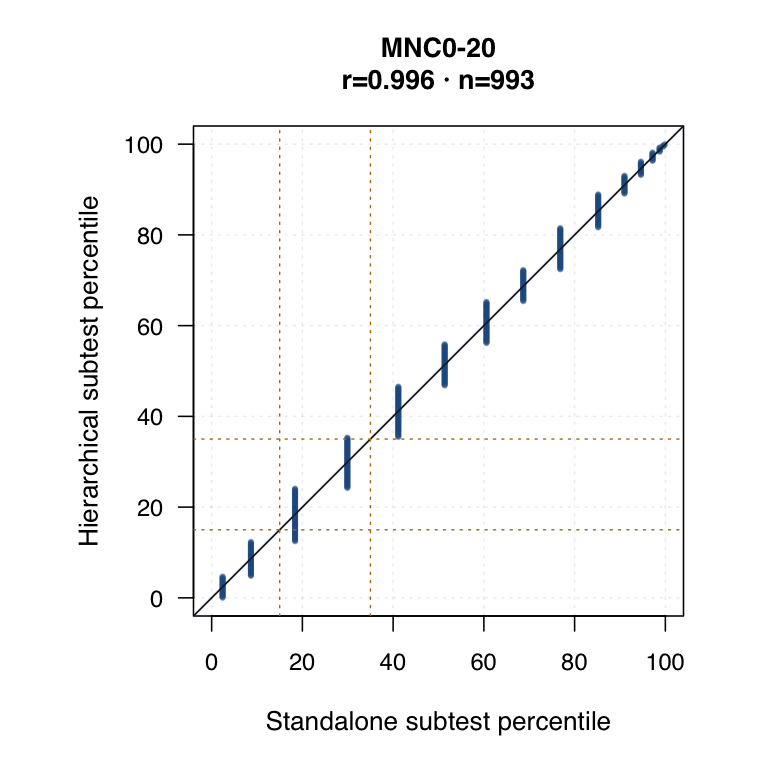
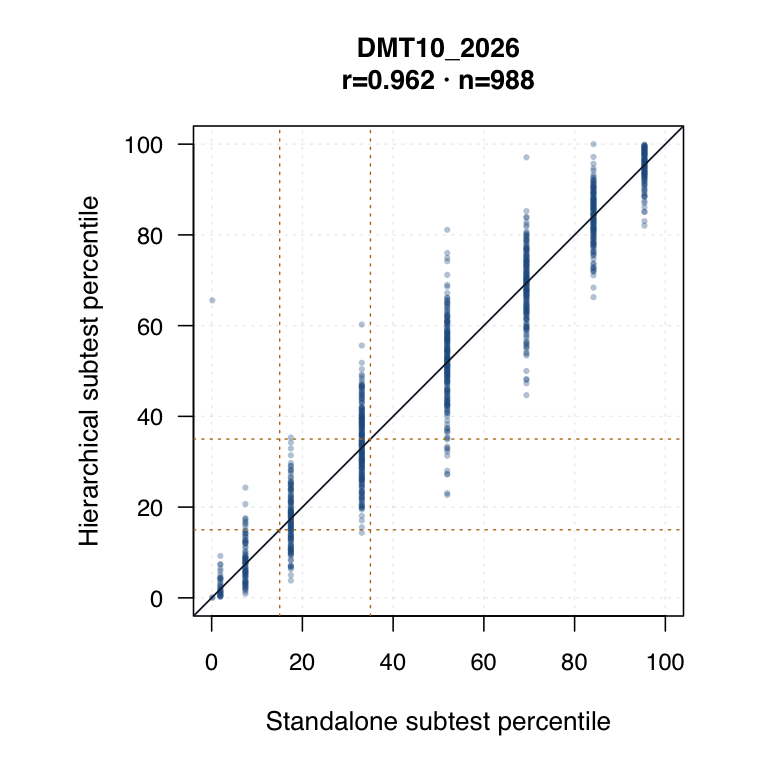
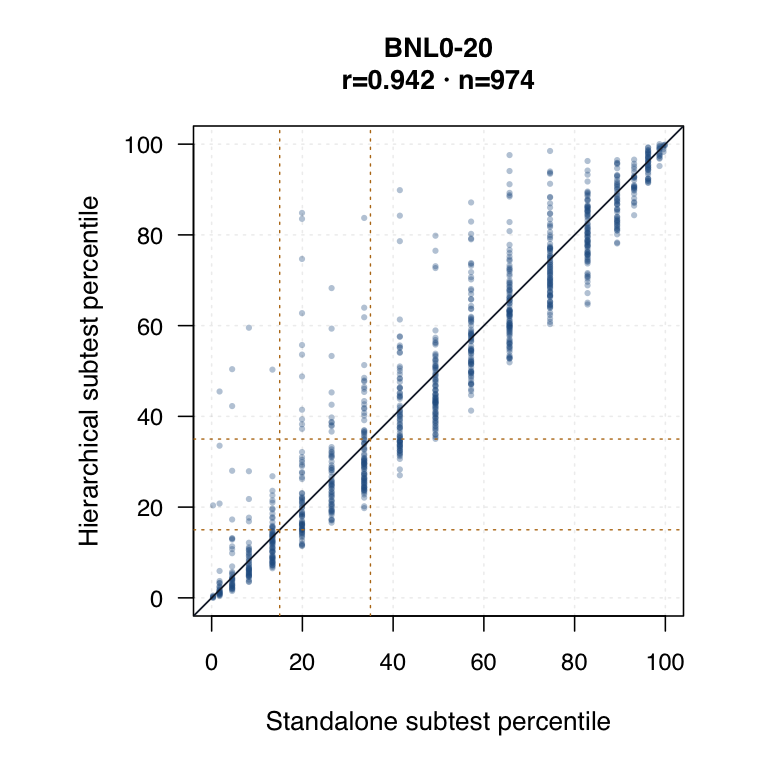
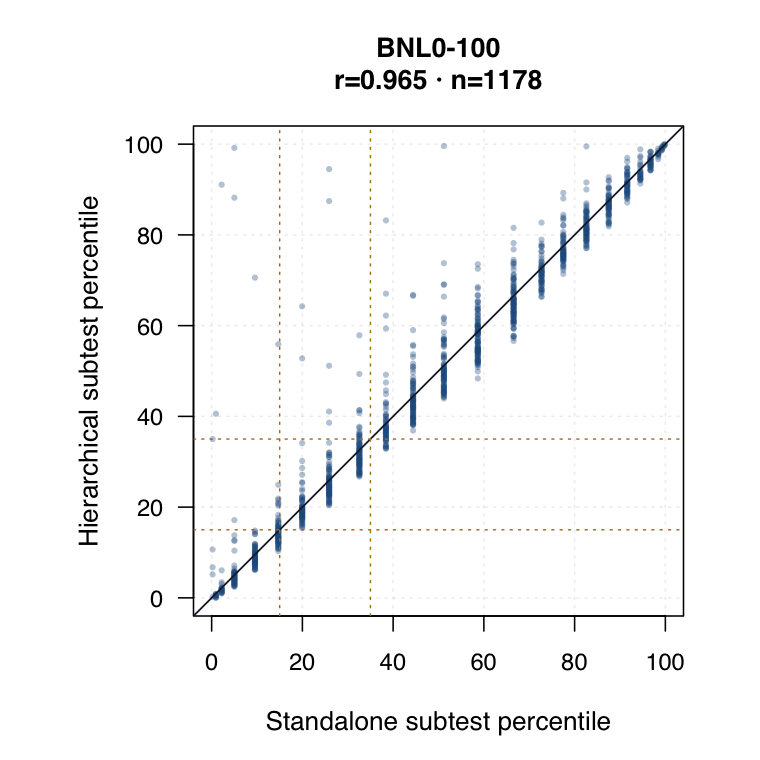
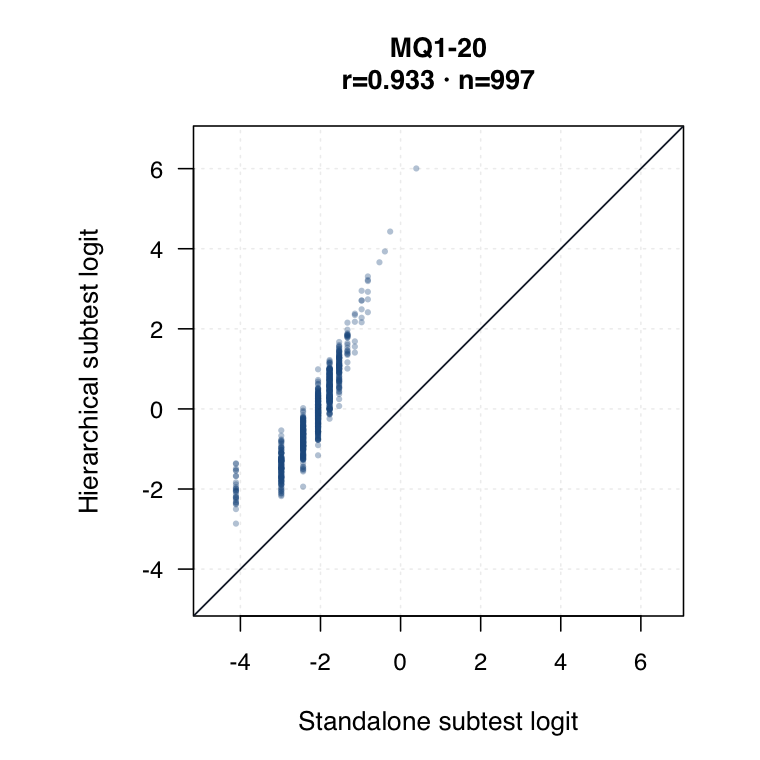
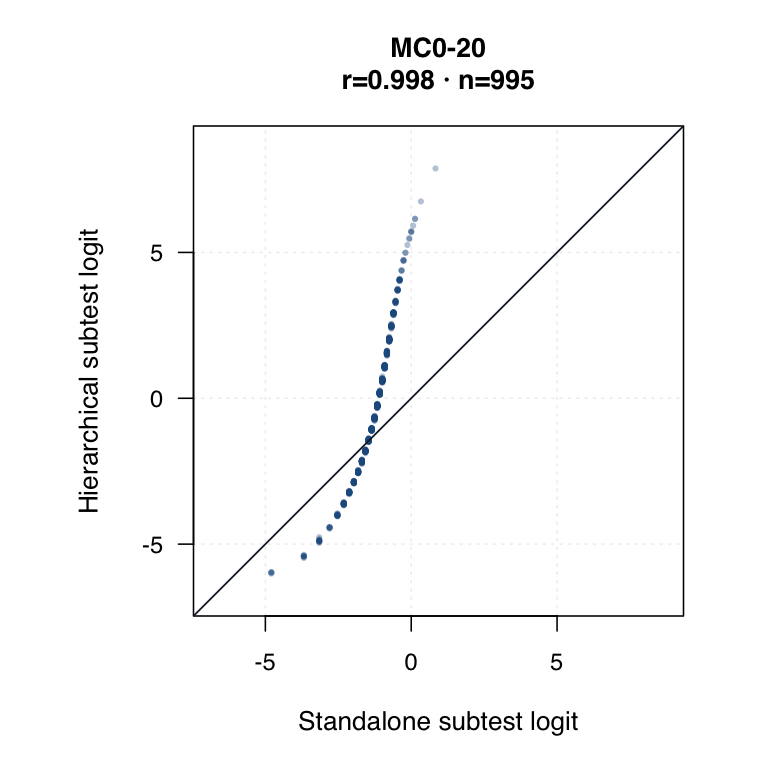
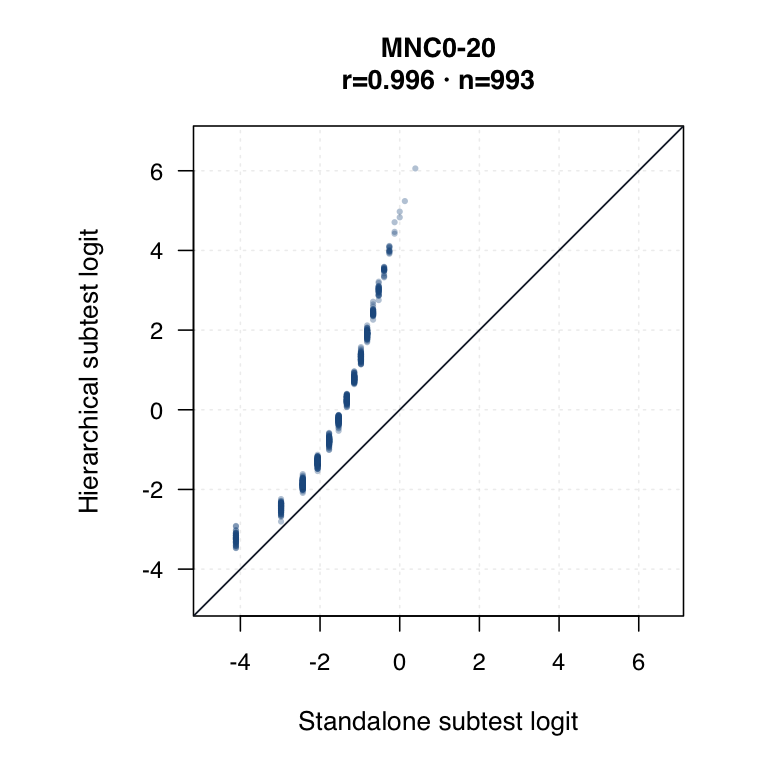
Hierarchical modelled subtest scores versus standalone subtest scores. Use the scale toggle to switch between percentile ranks and logits. Each dot is the same student ID; percentile plots mark the 15th and 35th percentiles.
Score what students answered correctly among valid reached responses. Cleaner as an accuracy or ability claim, but can understate timed productivity concerns.
Trailing unreached items receive zero credit. This intentionally blends accuracy, reach, pace and productivity.
Report accuracy and pace separately. Conceptually cleaner, but not the immediate BOY single-score decision.
Precision here means student-score uncertainty and band stability. The median values below summarise the typical student; the plots show the distribution across students where person-level uncertainty is available in the current artefacts.
| Method | Year level | Median posterior SD / SE | Median 90% interval width | Reliability-style summary | Read |
|---|---|---|---|---|---|
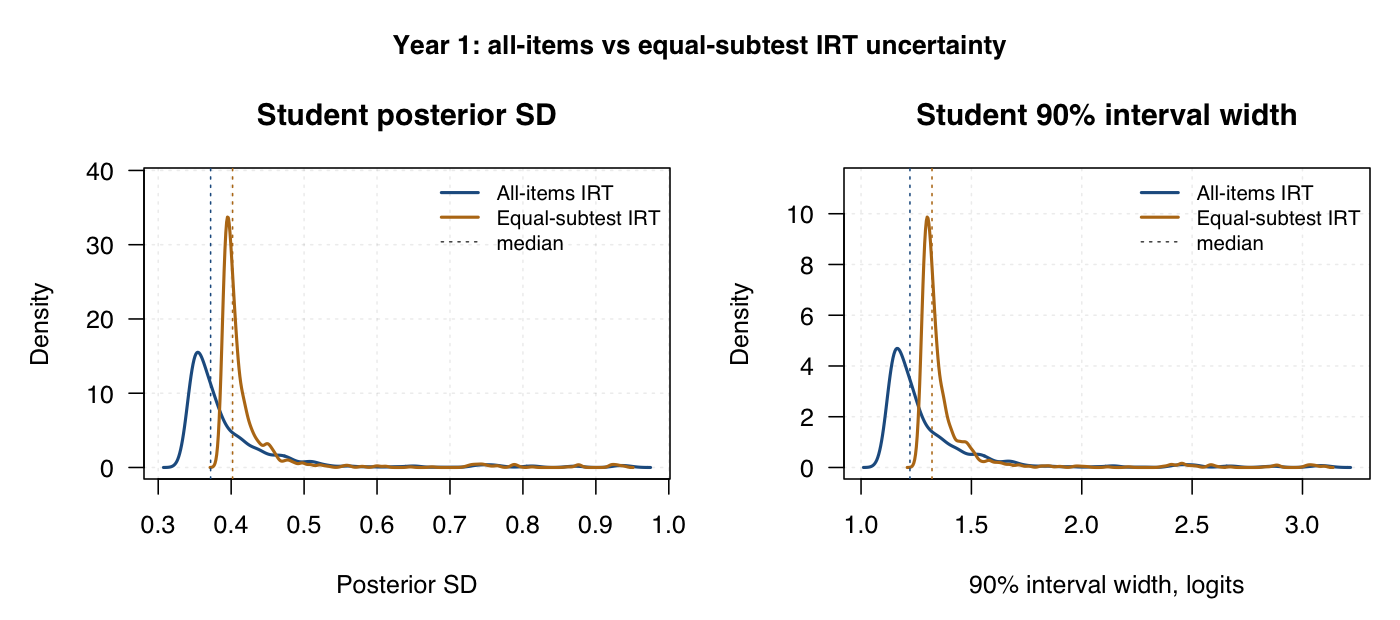
| All-items timed-performance IRT | Foundation | 0.491 | 1.614 logits | 0.665 | Usable global precision, but intervals are not narrow. |
| Equal-subtest timed-performance IRT | Foundation | 0.507 | 1.667 logits | 0.666 | Similar precision to all-items; equal weighting does not obviously improve precision. |
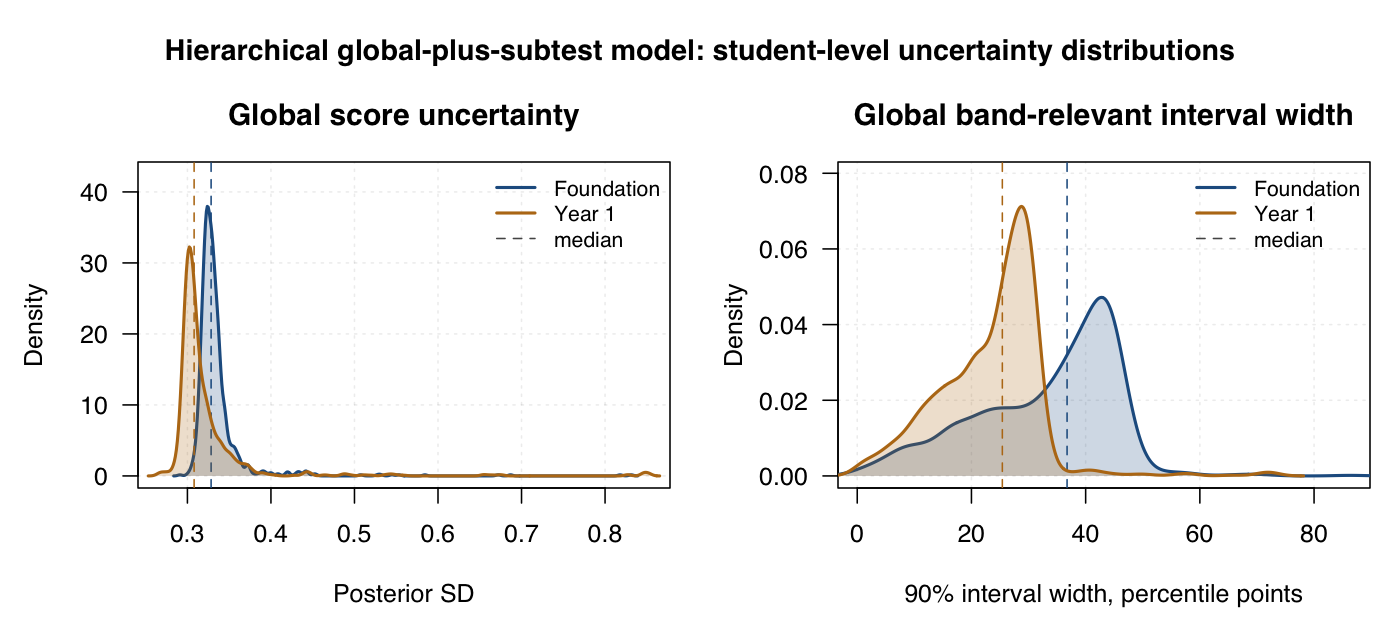
| Hierarchical global-plus-subtest global score | Foundation | 0.334 | 1.097 logits | 0.909 | More precise on its own scale, but the global interpretation differs. |
| All-items timed-performance IRT | Year 1 | 0.372 | 1.222 logits | 0.811 | Stronger global precision than Foundation. |
| Equal-subtest timed-performance IRT | Year 1 | 0.402 | 1.322 logits | 0.796 | Slightly wider uncertainty than all-items. |
| Hierarchical global-plus-subtest global score | Year 1 | 0.309 | 1.017 logits | 0.955 | Most precise global posterior, but not the same global score claim. |
Note: these summaries are not identical objects for every method. All-items and equal-subtest IRT posterior SDs are broadly comparable because they estimate similar one-score global IRT quantities. The hierarchical global posterior SD is for a pooled global component inside a global-plus-subtest model, so its smaller value should not be read as a direct precision win for replacing the all-items screener index. Standalone IRT uses SE-style quantities. Raw-score composites need a separate bootstrap or binomial approximation if we want comparable uncertainty.
These density curves use the completed policy-locked Stan person-score files. Blue lines are all-items timed-performance IRT; amber lines are equal-subtest timed-performance IRT.
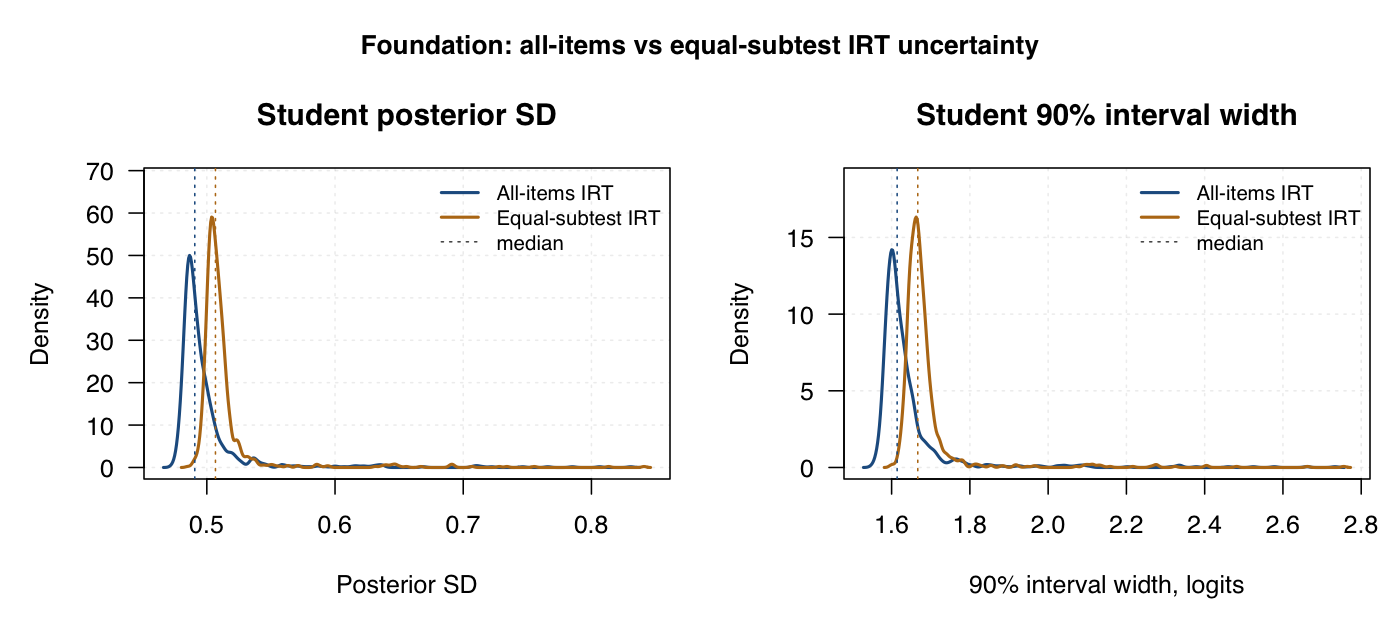
These density curves show how student-level uncertainty varies across students for the hierarchical global-plus-subtest model. Dashed lines mark medians.
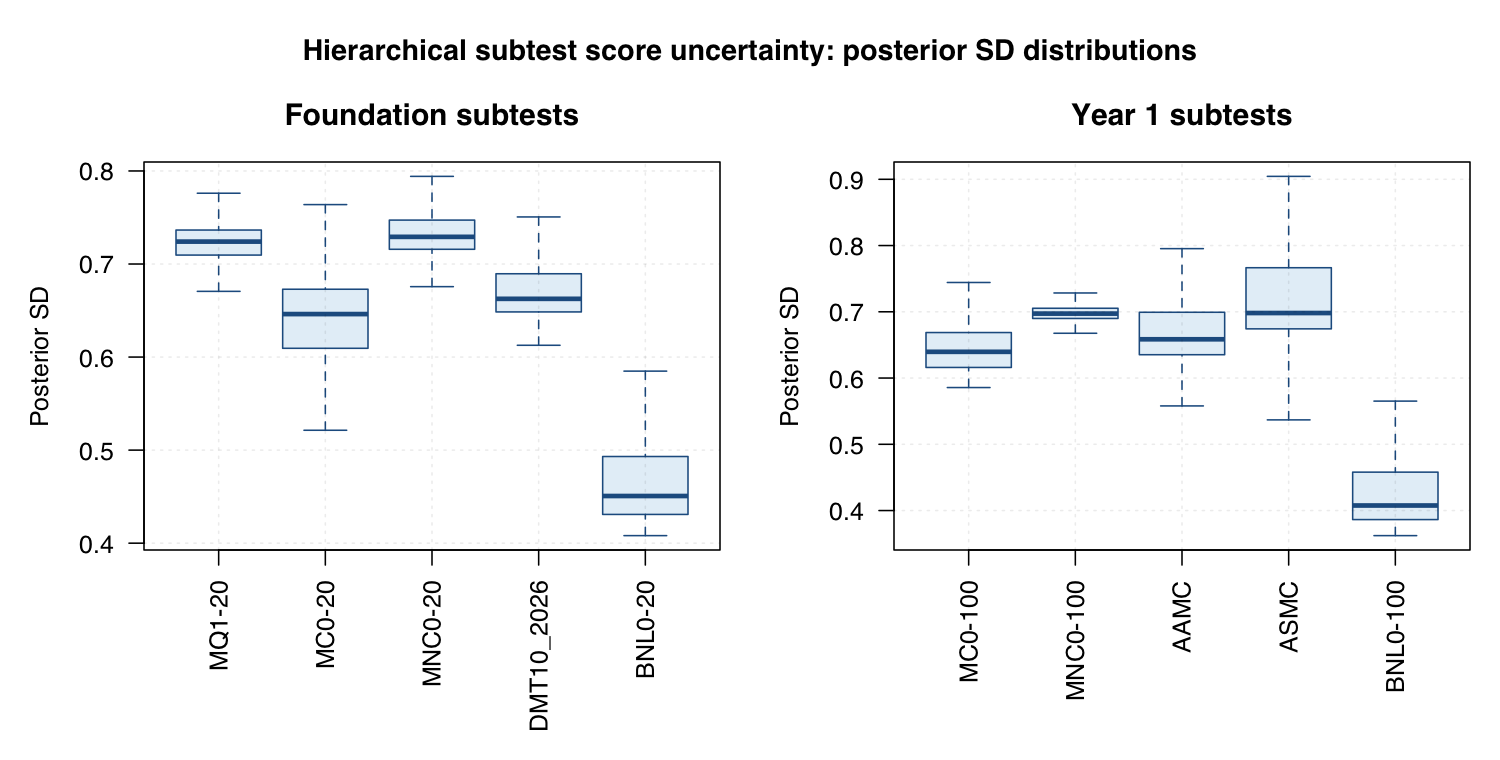
Subtest profiles are less precise than global scores. Wider posterior SDs mean subtest differences need more cautious interpretation.
| Score type | Year level | Median 90% interval width, percentile points | One-band interval | Three-band interval | Read |
|---|---|---|---|---|---|
| Global | Foundation | 30.8 | 49.6% | 12.7% | Many global intervals cross at least one dashboard band cut. |
| Global | Year 1 | 21.5 | 57.2% | 5.5% | Year 1 global bands are more stable. |
| Subtest | Foundation | 45.6 | 35.3% | 33.0% | Foundation subtest profiles need cautious, uncertainty-aware interpretation. |
| Subtest | Year 1 | 34.4 | 43.3% | 23.0% | Year 1 subtest profiles are more stable, but still not point-precise. |
Notation: student i, item j, subtest s(j), testlet t(j), scored response y. Equations below are schematic, intended to document the scoring architecture rather than every implementation detail.
Each retained item contributes once. For timed subtests, y uses timed-performance scoring.
The item model is similar, but likelihood contributions are weighted so subtests have equal design influence.
The model estimates a general score and subtest-specific deviations. Subtest scores are posterior summaries of θ_i,s.
This is direct observed scoring, not an IRT model.
Only selected subtests enter the global ability marker. Reliability weights r_s affect influence, but do not by themselves define construct importance.
Valid reached responses are scored 0/1. Trailing unreached items receive zero credit. Intermittent, contract, QC or other non-comparable missing rows remain missing.
Reliability can inform precision, uncertainty, shrinkage and reportability. It should not automatically determine construct importance. A reliable subtest can be narrow or misaligned; a noisier subtest can still represent an important domain.
The subtest-weighting sensitivity plots use completed policy-locked Stan person-score files for all-items and equal-subtest timed-performance IRT, matched by student GUID and re-ranked within year level. The subtest agreement plots join the GUID-keyed standalone subtest score export to hierarchical subtest posterior means by year level, subtest and the same student GUID. The default display converts scores to within-year × subtest percentile ranks; the logit toggle shows the same joins on the original model score scale.